Songkorpus
Multiply Annotated German Song Lyrics
Source: This example was kindly contributed by Roman Schneider, Leibniz Institute for the German Language, Mannheim, Germany
Systematically compiled collections of written and spoken texts form the most important empirical basis for linguistically motivated research on human language. Extensive data resources exist for standard and close-to-standard language varieties, supplemented by special corpora covering specific language situations and fields of application. Noteworthy against this background is the lack of scientifically valid, sustainably utilizable digital collections of pop lyrics, especially for the German language. Just as pop music has evolved from an originally youth cultural phenomenon in the nineteen-fifties and -sixties into an integral part of modern culture, its textual content has become omnipresent in the realm of everyday language. But unfortunately, song lyrics play a rather subordinate role in empirical language research so far - most likely due to the absence of scientifically valid, sustainable resources. Songkorpus (see the website at songkorpus.de) fills this gap, and provides the first multiply annotated corpus of German lyrics as a basis for multidisciplinary research. Besides linguistics and literature, benefiting research areas can be located in the broad spectrum of language didactics, musicology, (socio)cultural or media studies.
Our stratification objective is the comprehensive coverage of complete works, and not just the arbitrary compilation of some lyrics’ verses or phrases. Our corpus archives represent the works of selected singers/songwriters or bands who have kindly agreed to provide their lyrics for non-commercial, scientific research, spanning a period of about five decades. An additional archive includes German-language songs ranked in the official German Top 100 single charts since 1970, considering CD sales, internet downloads, and streaming platforms.
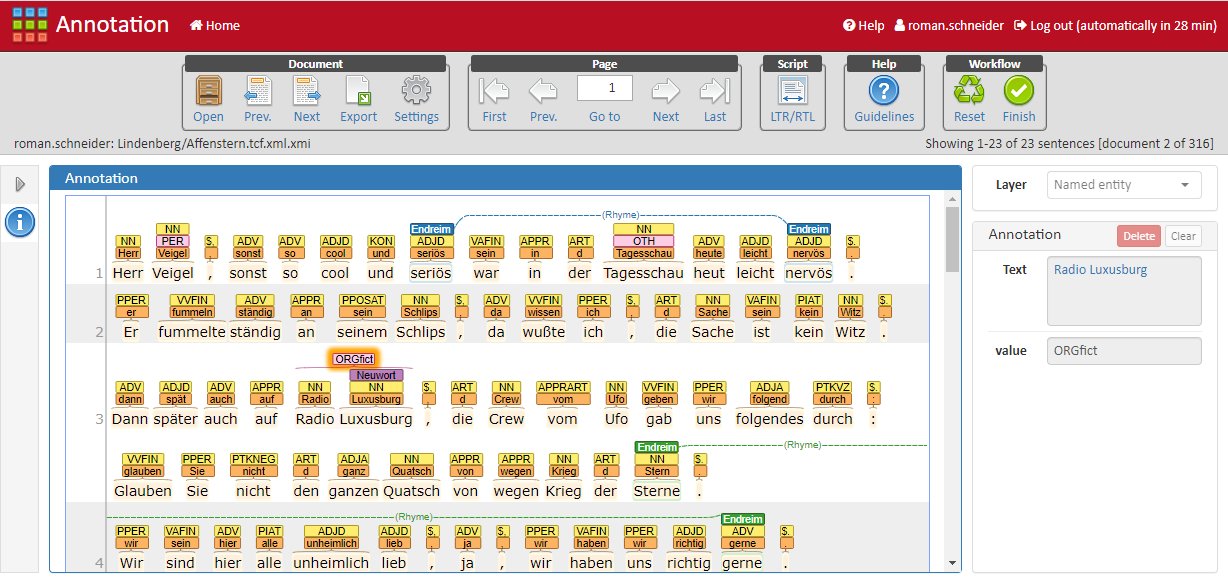
In order to cover various levels of granularity and to ensure interoperability, all lyrics are formatted using structural descriptions according to TEI P5. The corpus processing takes place as an interplay between automated annotation runs and manual post-editing. Results of the CLARIN infrastructure component WebLicht are imported into the web-based curation platform WebAnno. This allows the application of an extended POS tagset, the introduction of new classes for named entities, and special layers for neologisms and occasionalisms. Finally, a chain layer for the linking of rhyming words is added. All annotations – multiple classes, multiple annotators – are subject to inter-annotator reliability, using Fleiss’ kappa.
Publications
-
Schneider, Roman (2020). A Corpus Linguistic Perspective on Contemporary German Pop Lyrics with the Multi-Layer Annotated “Songkorpus”. In: Proceedings of LREC 2020 (Language Resources and Evaluation Conference), Marseille.
-
Schneider, Roman (2019). Konservenglück in Tiefkühl-Town – Das Songkorpus als empirische Ressource interdisziplinärer Erforschung deutschsprachiger Poptexte. In: Proceedings KONVENS 2019 (Konferenz zur Verarbeitung natürlicher Sprache), Erlangen. [PDF]