SemRelData
Semantic Relation Dataset
Source: This example was kindly contributed by Darina Benikova, Language Technology Lab, University of Duisburg-Essen, Germany
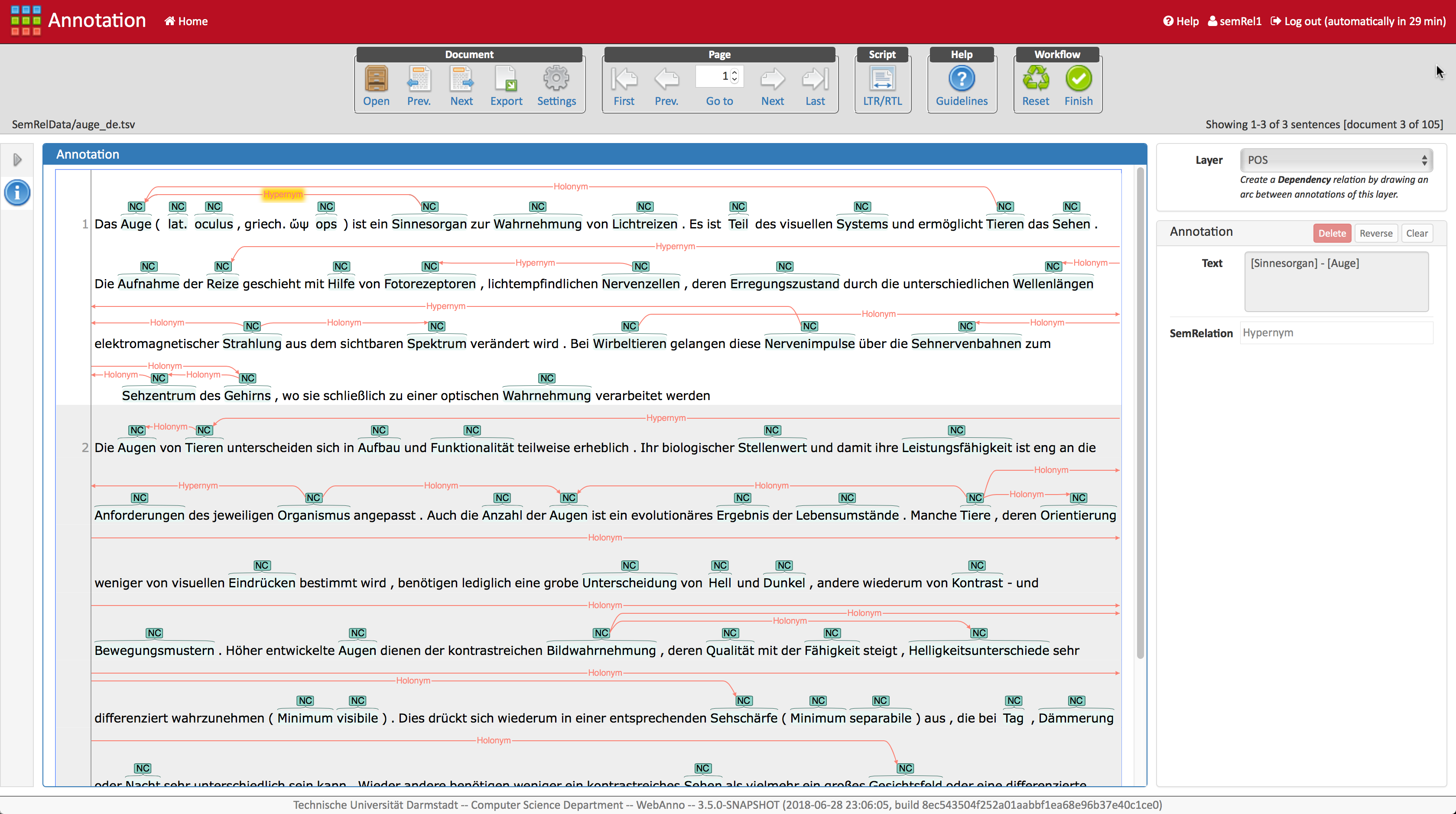
SemRelData (Semantic Relation Dataset) is a dataset focused on contextual annotation of classical semantic relations between nominals in various genres, i.e. encyclopedic, literary and news texts, and different languages, here: English, German and Russian.
It consists of texts extracted from three different genres – encyclopedic texts, extracted from Wikipedia; newspaper articles, extracted from Wikinews; and out-of-copyright literary texts. The dataset is distributed under a CC-BY license.
The resulting dataset consists of 13 news articles, 20 encyclopedic articles, and snippets from 9 literary texts, all available in parallel in the three described languages, and contains approximately 60,000 tokens, 15,000 noun compounds, 3,400 annotated relations and 9,400 transitive relations.
The dataset was created by a team of annotators in WebAnno using custom relation and span layers. The annotations were then compared and merged into a final annotation set using the curation functionalities.
Publications
- Darina Benikova (2015): SemRelData: Multilingual Contextual Annotation and Analysis of Semantic Relations between Nominals. MA Thesis, in collaboration with Sabine Bartsch (FB2, Technische Universität Darmstadt) [PDF]
- Benikova, Darina, and Chris Biemann (2016). SemRelData―Multilingual Contextual Annotation of Semantic Relations between Nominals: Dataset and Guidelines. LREC. 2016. [PDF] [BIB]